编码知识梳理
一直以来我对编码知识都倍感疑惑。借着这次整理书库的机会,把之前 joltwang(⺩王辉) 分享的编码知识ppt翻了出来,特此重新梳理一下
首先要搞明白一个问题, 那就是什么是字符
abcd算是 √®∑ø当然也算是 emoij表情符号也算是 夏でも底に冷たさをもつ青いそら 也算是
那什么是字符集呢
显而易见把具有相同特征的字符归纳整理到一个集合中就形成了字符集
那只有0,1表示的计算机是如何存储这些字符信息的呢?
这就涉及到了编码
-
字符编码的要素
-
首先要规定占用存储,也就是说一个字符需要几个字节来表示
-
生成编码规则下的编码表,也就是规定字符与字节序列间的一一对应关系
-
-
ASCII (American Standard Code for Information Interchange)
是基于拉丁字母的一套字符编码,占用一个字节,使用了一个字节中的7位,定义了128个字符,其中33个非显示字符,96个可显示字符
我们知道,在计算机内部,所有的信息最终都表示成一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000 到11111111
ASCII编码就是把英语字符和二进制位之间的关系,做了统一规定。比如空格是32(二进制 00100000), 大写字母A是65(二进制是 01000001)。ACSII只使用了后7位bit,每个字节的第一位bit统一为0。 空格当然算是可显示字符了,至于不可显示字符,多是一些陈废的操控文字的控制字符,但在DOS模式下可显示出一些诸如笑脸,扑克牌花式等符号。

ISO8859实际上是一种字符集标准——拉丁字符集,各个子集都有自 己的字符编码,共有14种字符编码。比如说iso-8859-1 扩展位放置的时德文字符, iso-8859-7 扩展位放的是希腊字符,这个标准存在的问题就是子集扩展部分互不兼容,只有拉丁字符部分相互兼容。
英文字符集: 26个字母;
简体字符集: 85000个,常用汉字:7000个。
简体字符的编码表远大于拉丁字符的编码表。
所以我们有了GB系列的编码
说说GB2312
借鉴 ISO8859 的编码思想,兼容ASCII,以两个字节为单位存储进行扩展。
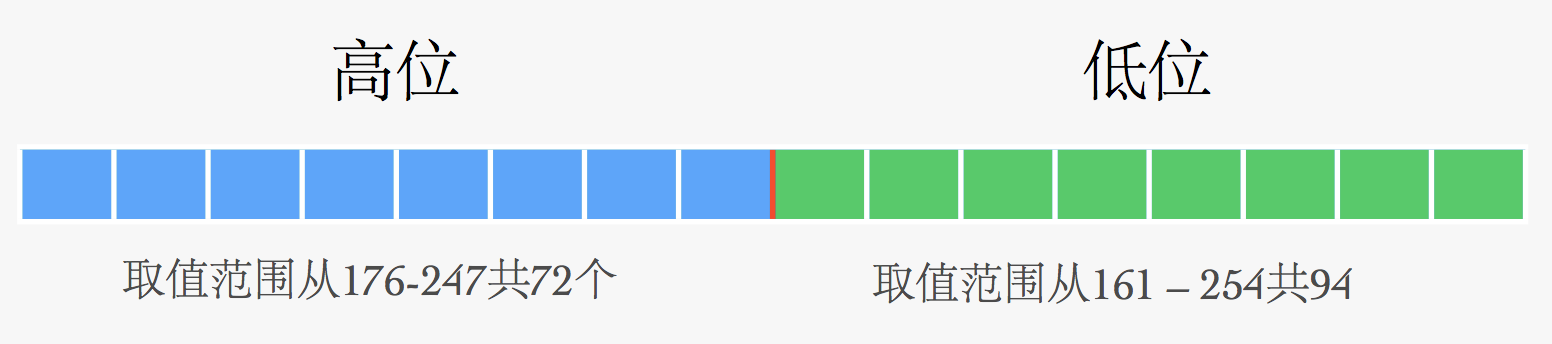
两个字节就有72 * 94 = 6768种可能,也就是可以表示 6768 种汉 字,GB2312实际收录6763个汉字,占常用汉字的99%。
存在的问题:很多汉字无法打印出来,比如朱镕基的“镕”,只能使用(金 +容)、(金容)、(左金右容)等来表示。
诸如此类的, 繁体中文有了 big5 编码, 韩文有了EUC-KR编码, 日文有了SJIS编码
这样依然存在问题, 这些编码集相互不兼容。
微软在发行windows95的时候发现了中文简繁体不能共存的问题, 所以提出了gbk编码,
GBK(kuozhan 扩展)是对GB2312的扩展, 最早实现于Windows 95简体中文版, 双字节存储。
包含了 gb2312 和 big5 + 少数民族 + 日韩东亚文字
后来我们国家又提出了 gb18030 编码标准, 被称为国标码 主要工作是对多名族语言的补充,采用多字节编码,每个字可以由1个、2个或4个字 节组成。
gk18030 包含了gbk以及更丰富的少数民族文字 藏文,满文等
但是gb18030 仍然解决不了国际化的问题。
这时候就需要诞生一个国际化的编码标准,首先出现的是一个字符集那就是unicode字符集。
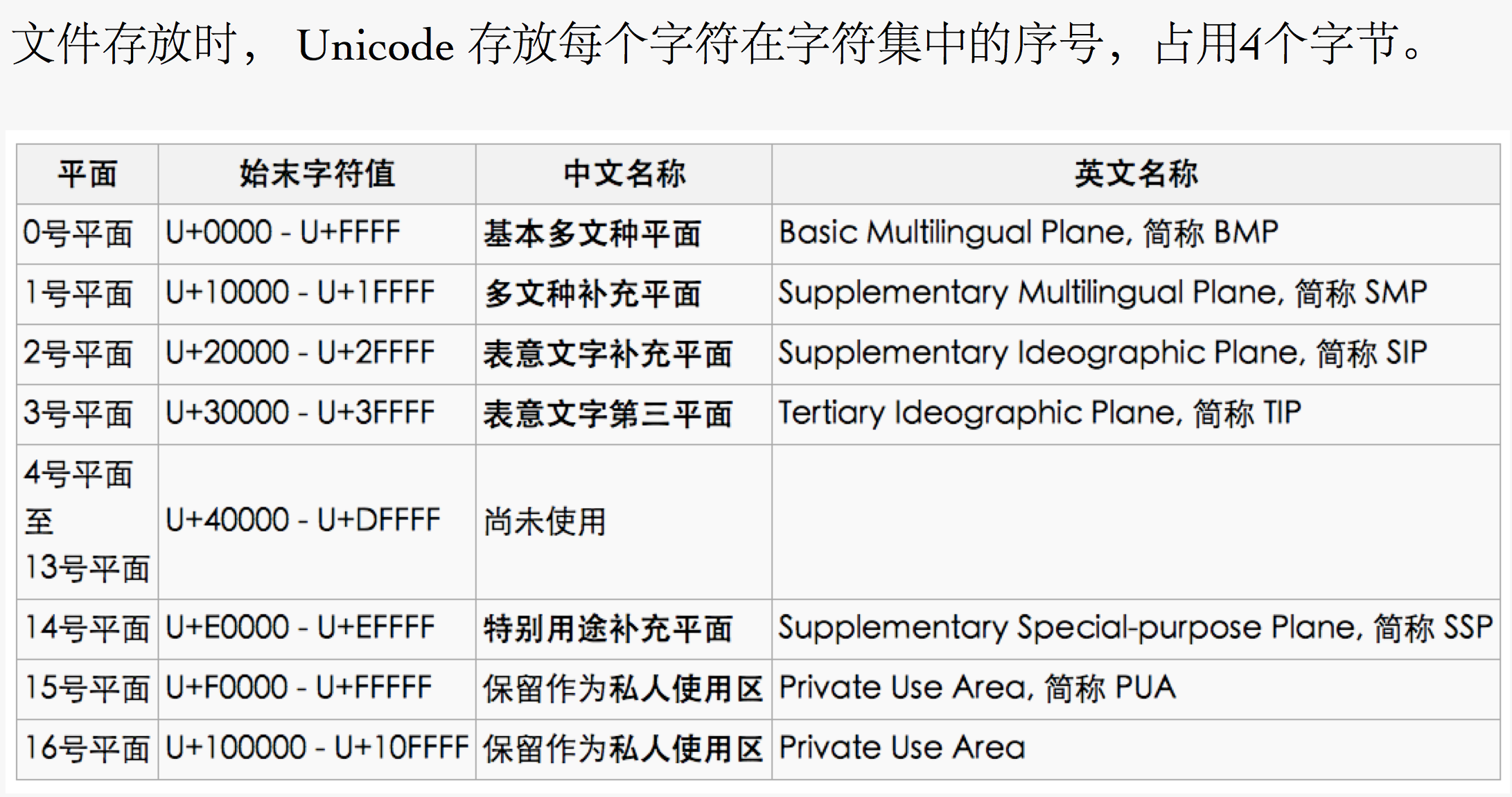

需要注意的unicode只是一个字符集, 它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉子“严”的unicode表示是4E25,转换成二进制足足有15位
100111000100101,也就是说这个负号的表示至少需要2个字节。表示其他更大的符号,可能需要3个或者4个字节,甚至更多。
这里就有两个严重的问题:
-
如何才能区分unicode和ascii? 计算机怎么知道三个字节表示一个符号而不是分别表示三个符号呢?
-
我们已经知道英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或者四个字节表示,那么每个英文字母前都必须有两到三个字节全部为0,这对于存储来说是极大的浪费,文本文件的大小会因此大出两到三倍,这是无法接受的。
所以就有了下边的结果:
-
出现了unicode的多种存储方式。也就是说有许多种不同的二进制格式,可以用来表示unicode字符集
-
unicode在很长一段时间内无法推广,直到互联网的出现
下边就来说一说各种编码方式:
-
UTF: unicode transformation format
-
utf-8: 可变长的
-
utf-16: 大部分是2个字节
-
utf-32: 4个字节
在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
chardata_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8编码
char16_tdata_utf16[]={0x6C49,0x5B57};//UTF-16编码
char32_tdata_utf32[]={0x00006C49,0x00005B57};//UTF-32编码
这里用char、char16_t、char32_t分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以char、char16_t、char32_t作为编码单位。(注: char16_t 和 char32_t 是 C++ 11 标准新增的关键字。如果你的编译器不支持 C++ 11 标准,请改用 unsigned short 和 unsigned long。)“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个char16_t,大小是4个字节。“汉字”的UTF-32编码需要两个char32_t,大小是8个字节。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。下面介绍UTF-8、UTF-16、UTF-32、字节序和BOM。[1]
-
utf-8
-
与ASCII兼容,这使得原来的软件无须或只须做少部份修改,即 可继续使用。 因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用 中,优先采用的编码。
UTF-8文件的Unicode签名BOM(Byte Order Mark)问题
近日在调测一个UTF8编码的中文Zen Cart网站时遇到一件怪事,网页显示文字正常,用ie的察看源文件(记事本打开)却发现乱码,firefox没有这个问题。经在网上多方查证和多次测试,解决了这个问题,其实是UTF-8文件的Unicode签名BOM(Byte Order Mark)问题。
BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测,而把它当作正常字符处理。
微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。
也就是说一个UTF-8文件可能有BOM,也可能没有BOM,那么怎么区分呢?三种方法。1,用UltraEdit-32打开文件,切换到十六进制编辑模式,察看文件头部是否有EF BB BF。2,用Dreamweaver打开,察看页面属性,看“包括Unicode签名BOM”前面是否有个勾。3,用Windows的记事本打开,选择 “另存为”,看文件的默认编码是UTF-8还是ANSI,如果是ANSI则不带BOM。
我找到Zen Cart的模版文件中的html_header.php,发现文件果然不带BOM,用UltraEdit-32另存为的方式加上BOM后,再上传html_header.php,一切正常。
注意用Convertz把gb2312文件转换成UTF-8文件时,默认设置是不带BOM的。不带BOM可能出现上述乱码问题,但是带 BOM,对于php的include文件要小心,会在php字节流前面多出EF BB BF,提前输出到显示器有可能会带来程序错误。一个解决方案是凡是被include的文件都保存为ANSI,主文件可以是UTF-8。要想把一个文件去掉 BOM,使用UlterEdit打开, 切换到十六进制编辑模式,把最前面三个字节(就是那该死的 EF BB BF)替换为20,保存(注意关闭保存时自动备份的功能),再切换到默认编辑模式,把最前面的三个空格去掉就可以了。
另外还学到一些编码的小知识:所谓的unicode保存的文件实际上是utf-16,只不过恰好跟unicode的码相同而已,但在概念上unicode与utf是两回事,unicode是内存编码表示方案,而utf是如何保存和传输unicode的方案。utf-16还分高位在前 (LE)和高位在后(BE)两种。官方的utf编码还有utf-32,也分LE和BE。非unicode官方的utf编码还有utf-7,主要用于邮件传输。utf-8的单字节部分是和iso-8859-1兼容的,这主要是一些旧的系统和库函数不能正确处理utf-16而被迫出来的,而且对英语字符来说,也节省保存的文件空间(以非英语字符浪费空间为代价)。在iso-8859-1的时候,utf8和iso-8859-1都是用一个字节表示的,当表示其它字符的时候,utf-8会使用两个或三个字节。
The UTF-8 BOM is a sequence of bytes (EF BB BF) that allows the reader to identify the file as an UTF-8 file.
Normally, the BOM is used to signal the endianness of the encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
According to the Unicode standard, the BOM for UTF-8 files is not recommended:
Short answer: In UTF-8, a BOM is encoded as the bytes EF BB BF at the beginning of the file.
Long answer:
Originally, it was expected that Unicode would be encoded in UTF-16/UCS-2. The BOM was designed for this encoding form. When you have 2-byte code units, it’s necessary to indicate which order those two bytes are in, and a common convention for doing this is to include the character U+FEFF as a “Byte Order Mark” at the beginning of the data. The character U+FFFE is permanently unassigned so that its presence can be used to detect the wrong byte order.
UTF-8 has the same byte order regardless of platform endianness, so a byte order mark isn’t needed. However, it may occur (as the byte sequence EF BB FF) in data that was converted to UTF-8 from UTF-16, or as a “signature” to indicate that the data is UTF-8.
几种编码格式的bom值
UTF-8
EF BB BF
UTF-16
FF FE
UTF-16 big endian
FE FF
UTF-32
FF FE 00 00
UTF-32 big endian
00 00 FE FF
-
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
Unicode编码(十六进制)UTF-8 字节流(二进制)000000 - 00007F0xxxxxxx000080 - 0007FF110xxxxx 10xxxxxx000800 - 00FFFF1110xxxx 10xxxxxx 10xxxxxx010000 - 10FFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxxUTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
移动比联通强的原因是记事本无法显示“联通”?
流言: ********************************** 在Windows操作系统中使用记事本新建一个文本文件,在文件里面写入“联通”两个字并保存。当再次打开这个文本文件时候,在记事本中看到得却不是刚刚输入的“联通”,而是乱码。这就是移动比联通强的原因! ********************************* 粉碎: 出现上述问题本质上是:GB2312与UTF-8编码冲突所致。首先普及一下编码常识: ASCII的霸权: 起初,是一些人想用8个晶体的亮灭表示世间万物,于是产生了“编码”,最早是美国人发明了ASCII字符集(American Standard Code for Information Interchange,美国信息互换标准代码)用来存储英文字符,一个字节8位,可以表示2^8=256个符号,其中0~32特殊用途(0x20以下);32~127 存储 英文;128~255为扩展字符集; GB2312的来历: 中国人想用电脑读写汉字,256个字符不够用怎么办?于是果断舍弃127之后没用的字符,并且在ASCII的基础上规定如果一个字符小于127则表示原字符,即所谓的半角字符,如果连续两个字符大于127则表示一个汉字,即全角字符。这就是GB2312,它实际是ASCII的中文扩展。 都来又有GBK,GB18030,都是对汉字字符集的扩充。 UNICODE的大一统: 一个叫 ISO (国际标谁化组织)的国际组织决定用16位来表示地球上所有文字,于是产生传说中的”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “UNICODE”。它规定两个字节为一个字符,英文高8位都是0,但问题是GBK 与UNICODE 在汉字内码编码完全不同。这为谣言埋下了伏笔…. UTF8的传输: 互联网上70%的内容是英文,而UNICODE英文高8位为0,如果采用UNICODE传输无疑造成空间浪费,于是产生UTF8即每次8个位传输数据,当然还有UTF16,UTF32,都是按一定规则转化后的编码形式。
这样就可以解释记事本不能显示的问题了,实际上,“联通”这两个字符的GBK编码具有UTF-8编码的特征,记事本犯下的错误正是将GBK编码存放的记录有“联通”两个字符的文件误认为UTF-8编码的文件。
细节(有兴趣看下): UTF-8编码采用1-3个字节对字符进行编码,编码字节数与字符的Unicode编码值有严格的对应关系,让我们回忆下UTF-8编码和Unicode的对应关系吧。
Unicode编码值 UTF-8编码结构 \u0001 - \u007E 0XXXXXXX \u0080 - \u07FF 和 \u0000 110XXXXX 10XXXXXX \u0800 - \uFFFF 1110XXXX 10XXXXXX 10XXXXXX
“联通”这两个字符的GBK编码值是“C1 AA CD A8”,GBK编码方式使用两个字节对一个字符进行编码,因此以GBK编码方式存放的录有“联通”两个字符的文件的大小为四个字节。接下来分别观察“联通”这两个字符GBK编码值的二进制形式,你有发现有趣的事。
联 GBK 十六进制:C1 AA 二进制:1100 0001,1010 1010 通 GBK 十六进制:C1 AA 二进制:1100 1101,1010 1000
请注意上面二进制数据的着色部分,你想到了什么?对,它们和UTF-8编码结构中的补充位完全一致,UTF-8编码的补充位使得编码值更有规律,而记事本刚好凭借这个特征区分UTF-8编码的文件。存有“联通”两个字符的文件的所有数据都符合这个特征,就是这样,记事本彻底的将文件误认为UTF-8编码的文件。 将错就错,让我们来看看这个错误是怎样收场的。如果把“联通”的GBK编码值当作UTF-8编码值,那文件就成为一个写有数据“C1 AA CD A8”并以UTF-8编码的文件,当使用记事本再次打开的时候会看到什么呢?只要将UTF-8编码转换成Unicode编码就知道了。UTF-8编码“C1 AA CD A8”转换成Unicode编码后,编码值为“6A 00 68 03”(转换方法请参考本Blog中的《字符编码》一文)。0x006A这个Unicode编码值位于\u0001 - \u007E之间,若要转换为UTF-8编码,显然只能用一个字节进行编码,因此“联”的GBK编码“C1 AA”虽然特征上貌似UTF-8编码,但它却不对应任何一个UTF-8编码。接着看0x0368这个Unicode编码值,这个值对应了字符“ͨ”,这也正是我们将在记事本中看到的内容。或许你会说我看到的是一个黑色矩形啊,这只是字体的原因,你将字体改为宋体或者其他字体,看到的就是字符“ͨ”。 对于中文字符,UTF-8编码要用三个字节进行编码,因此,如果你使用记事本录入“联通”,然后选择以UTF-8编码方式保存的话,文件大小应为9个字节(包含三个字节的开头数据),而同样的文件GBK编码却是4个字节。
-
-
utf-16
UTF-16编码以16位无符号整数为单位。我们把Unicode
unicode 编码记作U。编码规则如下: 如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数(为书写简便,下文将16位无符号整数记作WORD)。
如果U≥0x10000,我们先计算U’=U-0x10000,然后将U’写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
为什么U’可以被写成20个二进制位?Unicode的最大码位是0x10ffff,减去0x10000后,U’的最大值是0xfffff,所以肯定可以用20个二进制位表示。例如:Unicode编码0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,即0xD843 0xDC30。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate): 这里的意思是 unicode编码表中0xD800-0xdfff 是没有被赋予任何的字符的,永远不会有单个字符落在这个区域。
D800-DB7FHigh Surrogates高位替代DB80-DBFFHigh Private Use Surrogates高位专用替代DC00-DFFFLow Surrogates低位替代下边这段高替代位, 低替代位的知识会很难懂, 所以我在最后补充了另外一篇知识。
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。 如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。我们将这个范围写成二进制: 1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111 按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到 1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代[1]。
四字节的UTF-16字符的性质与计算
JavaScript中的字符串是以UTF-16为代码单元。通常我们使用的字符范围都在Unicode值0x10000以内,他们对应的UTF-16就是它们自身。但Unicode中也存在这个范围之外的字符,这时候就需要两个UTF-16字符来描述。这些字符在统计时会被作为两个字符。 比如下面这个字符,虽然只有一个字,但却会统计出两个字符。
<script> alert("𠐀".length); //2 </script>因为字符串的length表示的并不是字符个数,而是UTF-16的单元个数。Unicode为UTF-16预留了两块区域,称为“高位替代区”和“低位替代区”。这两个区域的字符单独使用是每一意义的,甚至在某些地方都无法单独使用他们,比如内置的URL转义函数就无法转换这样的字符
比如说直接使用encodeURIComponent(“\uD841”) 是会直接报错的
在正则表达式中,其也是被作为两个字符来处理的 /^.$/.test(‘’) false /^..$/.test(‘’) true
使用charCodeAt的时候也会把它作为两个字符来处理。这些把它当做两个字符处理的情况会分别处理它的“高位替代符”和“低位替代符”。
-
utf-32
UTF-32
UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。 字节序
字节序有两种,分别是“大端”(Big Endian, BE)和“小端”(Little Endian, LE)。 根据字节序的不同,UTF-16可被实现为UTF-16LE或UTF-16BE,UTF-32可被实现为UTF-32LE或UTF-32BE。例如:
Unicode编码UTF-16LEUTF-16BEUTF32-LEUTF32-BE0x006C4949 6C6C 4949 6C 00 0000 00 6C 490x020C3043 D8 30 DCD8 43 DC 3030 0C 02 0000 02 0C 30Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
最后得出的结论:
• 新产品上线尽量使用UTF-8编码,避免多编码存在的混乱局面, 并且满足国际化;
• 根据业务需求和容量,避免不必要的浪费,例如日志的存储。
• 发送HTTP请求的时候,注意你的字符编码,一定要与上下游接 收方保持一致。